Velocity technical overview
Turn scattered company knowledge into answers your team can verify.
Velocity is a governed enterprise knowledge assistant for organizations whose answers live across documents, SaaS apps, and PostgreSQL. It gives leaders one permission-aware workspace for grounded chat, SQL analysis, source management, and multi-tenant administration.
Built by TierOne as proof of the engine: React on the front, NestJS on the back, Airweave and Qdrant for retrieval, OpenAI and LangChain for the agent runtime, and PostgreSQL as the control plane.
Engineering is what humans do. Code is what tools produce. Code is cheap. Operators are made.
Project scoped conversation
Operations intelligence
Which customer region grew fastest last quarter, and what document explains the change?
searching attached project sources...
The fastest growth came from LATAM. The supporting report points to expansion in customer success coverage and a shorter onboarding pipeline.
q1-2026-report.pdf customers.regionSELECT region, growth_rate FROM customers_region ORDER BY growth_rate DESC LIMIT 3; rows: 3 duration: 412ms mode: read-only
Measured evidence
Not a demo script. A measured RAG run.
On June 11, 2026, Velocity ran 100 questions through the real chat UI against a six-document benchmark corpus. The result is an engineering baseline, not a blanket production guarantee.
Strict accuracy
Pass-only score across 100 questions.
Lenient score
Pass plus partial answers.
Hit@3
Expected document in the top three source chips.
p95 latency
End-to-end answer latency through the UI.
What the benchmark proved, and what it did not.
When the expected document was retrieved first, answers were almost always right. The four hard misses traced back to retrieval gaps, table chunking, terminology mismatch, or long-thread contamination. That is useful because the failure is diagnosable; it gives the team a concrete tuning path instead of a vague "AI quality" complaint.
The next production step is customer-domain evaluation: representative questions, expected evidence, refusal cases, route choice, latency, and cost thresholds for the specific pilot workflow.
Example source document from the synthetic benchmark corpus, used to test source-grounded retrieval.
What Velocity does
A governed conversational layer over the systems your team already depends on.
Operational questions usually force a leader to know the right system, request access, understand the schema, combine evidence, and explain the answer. Velocity compresses that workflow into a project-scoped conversation.
Projects as context
Each project binds a business domain to approved Airweave collections, SQL connections, vector databases, and chat conversations.
Grounded answers
Document answers carry citations. Database answers expose SQL execution details, row count, truncation, duration, and source identity.
Permission-aware work
Navigation is filtered by role, but the API rechecks every protected operation through organization scope and action-level permissions.
Admin control plane
Managers and admins handle organizations, users, sessions, roles, approvals, impersonation, sources, and project lifecycle.
Value for the user
Less hunting. More decision-grade evidence.
Velocity is for executives, analysts, operators, managers, admins, platform superadmins, and developers who need natural-language access without handing every user raw credentials or direct infrastructure access.
Faster decisions
Ask a business question without learning every source UI, table name, or internal runbook location.
Governed access
Credentials stay server-side. Project sources and organization membership define what the agent can use.
Traceability
Answers show citations or SQL execution metadata so users can inspect evidence instead of trusting a black box.
Incremental adoption
Start with one bounded workflow, one organization, one project, and one or two approved sources.
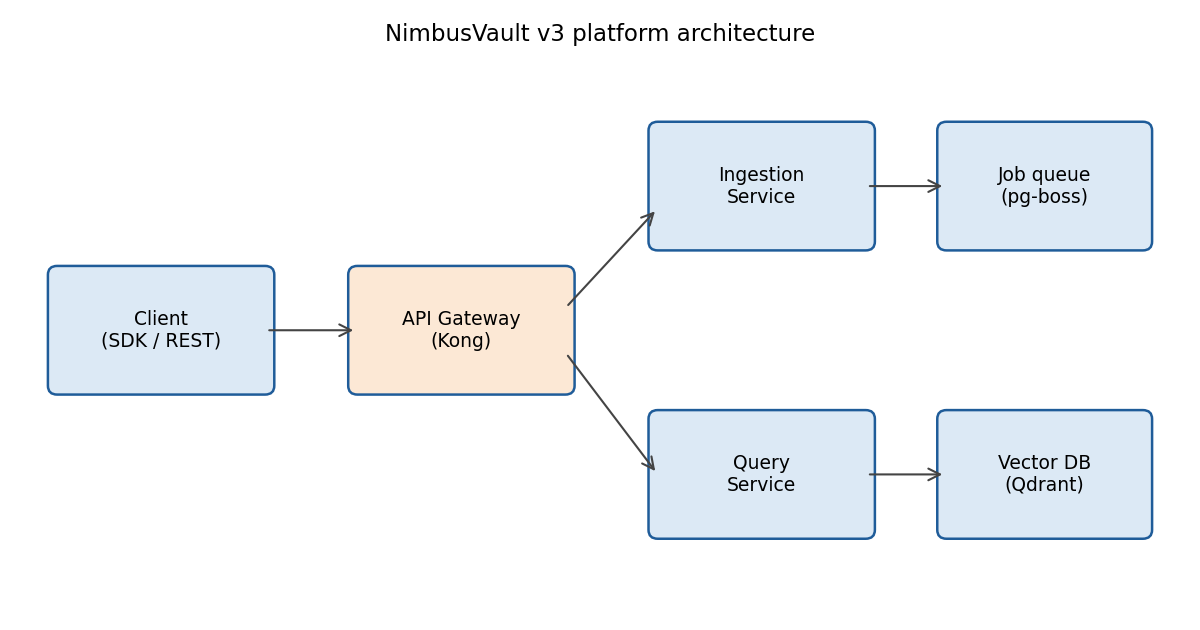
Architecture
Two repos. One product boundary. No credentials in the browser.
The SPA owns the user experience. The API is the trusted execution boundary for identity, permissions, source resolution, LLM calls, SQL execution, document ingestion, and persistence.
React workspace
Routes, forms, RBAC-aware navigation, chat UI, SSE rendering, and source management.
NestJS boundary
Guards, services, domain ports, agent runtime, persistence, and external adapters.
Source plane
PostgreSQL, Airweave, S3, Qdrant, OpenAI, pg-boss, and Resend.
Frontend implementation
The frontend is a React 19 and TypeScript SPA built with Vite 7. It uses React Router 7 for routing, TanStack Query for server state, Zustand for client state, React Hook Form and Zod for forms, Tailwind 4 with Radix UI/CVA for the design system, and Better Auth's browser client for bearer sessions.
Backend implementation
The backend is a modular NestJS 11 service with clean/hexagonal module boundaries: API controllers, application services, domain ports and entities, and infrastructure adapters. It uses Better Auth, PostgreSQL, TypeORM, LangChain, OpenAI, Airweave SDK, S3, Qdrant, pg-boss, Resend, Jest, Supertest, and Testcontainers.
Agentic implementation
The model chooses tools inside boundaries humans defined.
We don't build rosters. We build engines. In Velocity, the engine starts with a project boundary, builds tools only from ready sources, then routes the question through RAG, SQL, or the general agent lane.
01 / Project tools
Only ready sources are exposed.
Before execution, Velocity resolves the conversation, checks project ownership, loads attached sources, filters to `ready`, and asks the data-source registry to build the available tools.
02 / Router
Confident questions take a direct lane.
An optional classifier routes high-confidence questions to direct RAG or direct SQL. Low confidence, malformed JSON, or ambiguous questions fall back to the general agent path.
03 / Outer agent
Ambiguous work uses tool-calling.
The LangChain outer agent receives project context, recent history, source descriptions, `search_knowledge_base`, and `query_database` when database sources exist.
RAG lane
Search across Airweave and Velocity vector databases.
Retrieval fans out across ready search-capable sources, tolerates one provider failure without failing the entire query, deduplicates results, caps context, and returns citation metadata. Velocity-managed documents move through S3, pg-boss, text extraction, OpenAI embeddings, and Qdrant.
SQL lane
A dedicated SQL sub-agent answers with executed data.
The `query_database` tool resolves an organization-owned connection, decrypts credentials, inspects permitted schema, generates one read-only statement, executes it under limits, shapes the result, and sends SQL metadata back to the UI.
conversation -> project -> ready sources -> data-source registry
-> router: rag | sql | agent
-> search_knowledge_base # Airweave + Qdrant, bounded citations
-> query_database # org-owned Postgres, read-only SQL
-> synthesis # streamed SSE chunks + metadata
-> persisted assistant reply # no raw SQL result rows in message metadata
Governance and safety
The LLM is never the security boundary.
Velocity's strongest engineering choice is boring on purpose: permissions, tenant scope, credentials, SQL safety, and source ownership are enforced outside the model.
Authorization
Better Auth bearer sessions, approval states, active organization membership, data-driven roles, and action-level permissions.
Tenant isolation
Organization scope in guards, services, repository predicates, source ownership checks, and explicit superadmin cross-organization paths.
SQL controls
AES-256-GCM credentials, host validation, single-statement allowlists, read-only transactions, timeouts, row limits, byte limits, and sanitized errors.
Source lifecycle
Airweave ownership allowlists, S3 file storage, pg-boss ingestion jobs, Qdrant retrieval, source readiness, and destructive-operation protections.
Where Velocity fits
Strong platform foundation. Honest pilot boundary.
The docs are explicit: Velocity is suitable for a controlled enterprise pilot with bounded data, named owners, and human review. That honesty is part of the product.
Good first use cases
- Recurring questions across internal documents and PostgreSQL data.
- Project owners who can approve which sources belong in each workspace.
- Users who need natural-language access with visible evidence and human review.
- A bounded pilot where answer quality, refusals, route choice, latency, and cost can be measured.
Readiness decisions before broad rollout
- Data-processing, retention, residency, subprocessors, and provider terms.
- Durable audit logs for privileged operations and destructive changes.
- SLOs, backup/restore, recovery objectives, and dependency-aware readiness.
- Customer-domain evaluations, prompt-injection tests, and cost controls.
Why TierOne built it
Velocity is the product version of the TierOne thesis.
Anyone can wire a chatbot to a document store. The hard part is the engine around it: tenancy, permissions, source lifecycle, retrieval quality, SQL boundaries, operator-owned evaluations, and the discipline to say where the system is not ready yet.
That is the difference between AI theater and operator-led engineering. We don't build rosters. We build engines.
Build the next engine
If your AI system has to survive production, start with the operating model.
Run the free Engine Diagnostic, then bring the result into a Sprint conversation. We'll tell you where the system breaks first, what to assemble, and what not to build yet.